



Any document in Atlantis can contain not only ordinary text and pictures but also tables.
Tables are divided into rows and columns.
The following table has 3 rows, each highlighted with a different color:

A table row consists of one or more cells. There are 5 cells in the following table row, each highlighted with a distinctive color:
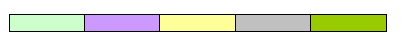
Cells sharing same left and right edges constitute table columns. There are 5 columns in the following table, each highlighted with a distinctive color:
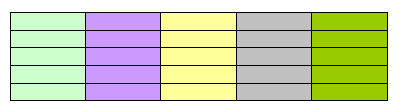
Each table row can have its own number of cells, and each cell can have its own specific width:
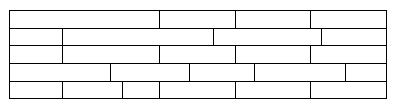
Rows can have different widths within the same table:
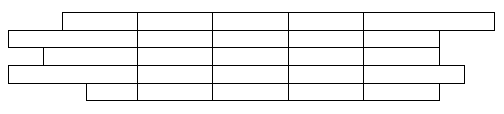
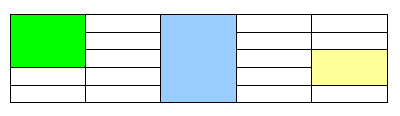
A table can contain vertically merged cells spanning multiple rows. In the following table, the merged cells are highlighted, each with a different color:
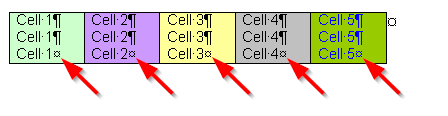
Each table row is terminated with an end-of-row mark — a special symbol "¤" which becomes visible only under the "View | Special Symbols" mode:

In the same way, each cell is terminated with an end-of-cell mark — a similar symbol "¤" which becomes visible only under the "View | Special Symbols" mode too:
A table cell can have a border on any of its sides. In the following table, all 5 cells have borders on all sides:
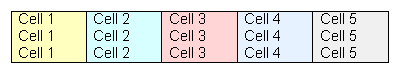
On the other hand, the following table is entirely borderless:
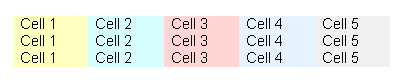
When the "Table | Gridlines" menu command is checked in Atlantis, the boundaries of borderless cells are displayed as dotted lines:
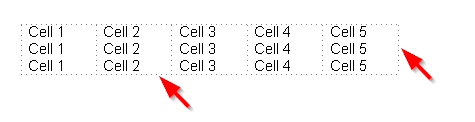
Note that these gridlines are displayed only on screen. They are never printed on paper.
In Atlantis, you can design as many different table layouts as you want, from simple to most complex.
See also...



