


This version of Atlantis Word Processor is a minor release with a much improved Find & Replace feature. Please read on for details.
Wildcards and regular expressions
Repetition counters @ and {n,m}
Parentheses () and group backreferences \n
Wildcards and regular expressions
This version of Atlantis adds support for regular expressions to the "Find & Replace" feature. Regular expressions can be used to find text that matches a given pattern and optionally replace those matches with new text.
A regular expression can contain ordinary text and wildcards. A wildcard is a character that can be used to represent one or many characters.
To search for patterns through regular expressions, the "Find & Replace" dialog now includes a "Use wildcards" option:
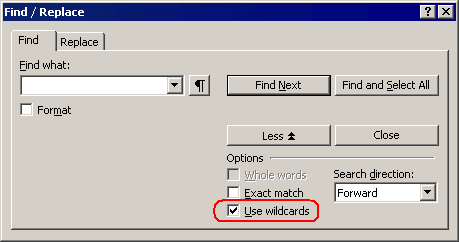
When this box is checked, the search patterns that you enter in the "Find what" or "Replace with" boxes are treated as regular expressions.
When this box is unchecked, all wildcards are treated as ordinary characters with no special meaning, and Atlantis performs an ordinary search.
Here are the wildcards that you can use to compose regular expressions in Atlantis:
? and *
"?" is the most basic wildcard. It matches any single character. For example, the "c?t" expression matches "cat" and "cut".
"*" (the asterisk) matches any string of characters (including a blank string containing no characters at all). For example, "be*st" matches "best", "beast", "behest", and "bee from the nest". In this example, the asterisk returns all characters that lie between "be" and "st".
< and >
"<" matches the beginning of a word. For example, "<comp" matches "comp" in "international competition", but does not match "comp" in "recompile".
">" matches the end of a word. For example, "ter>" matches "ter" in "character spacing", but does not match "ter" in "terrifying".
"<<" matches the beginning of a paragraph. For example, "<<1." matches "1." at the beginning of a paragraph.
"<<" can be used in conjunction with "<". For example, "<<<*>" matches any word at the beginning of a paragraph.
Character sets [ ] and [! ]
Square brackets "[ ]" can be used to specify a set of characters. A character set always matches only a single character in the document text. For example, "[aeo]" is a set of three characters "a", "e", and "o". "[aeo]" matches any single one of these three characters. For example, "b[aeo]t" matches "bat", "bet", and "bot".
You can specify entire ranges of characters within character sets. For example "[a-z]" matches any letter from "a" to "z".
Note that the ranges must be in ascending order. You can specify "[a-z]", but not "[z-a]".
You can have both individual characters and character ranges within the same character set. For example, "[b-df-hj-np-tv-xz]" matches any English consonant. It contains 5 character ranges: from "b" to "d", from "f" to "h", from "j" to "n", from "p" to "t", and from "v" to "x". It also includes 1 individual character "z".
You can compose character sets matching any characters except the characters included in the character sets. This is done by putting "!" after the opening bracket "[" of the character set. For example, "[!a-e]" matches any character except the characters included in the specified range, i.e. the "a", "b", "c", "d", and "e" characters.
If you want to include a hyphen "-" or an exclamation mark "!" as literal characters in a character set, you need to "escape" them, i.e. neutralize their special meaning. This is done by putting a backslash "\" right in front of them. For example, "[\!\-]" matches any exclamation mark or hyphen.
To include the backslash character itself as an ordinary character in a character set, you need to escape it too. For example, "[1\\2]" matches either the digit "1", or the backslash character "\" (represented by "\\"), or the digit "2".
Repetition counters @ and {n,m}
"@" and "{n,m}" can be used to specify how many occurrences of the previous character or expression should be found.
"@" means "one or more occurrences of the previous character". For example, "bo@t" matches "bot" and "boot".
The "{n,m}" counter can be used in three different ways:
- {n}" means "exactly n occurrences of the previous character or expression".
For example, "<[0-9]{3}>" matches any 3-digit number: "115", "298", "952", etc. - {n,}" means "at least n occurrences of the previous character or expression".
For example, "<t[a-z]{3,}d>" matches any word beginning with "t", ending with "d", and containing at least 3 characters in between "t" and "d", like for example "tired", "talked", "treated", "transferred", etc. - {n,m}" means "from n to m occurrences of the previous character or expression".
For example, "<[a-z]{3,6}>" matches any word containing 3, 4, 5, or 6 characters, like for example "bat", "font", "break", "search".
Note that "n" in the "{n,m}" counter can be 0 . This means that zero occurrence of the preceding character or expression is allowed. For example, "<[0-9]{4}-{0,1}[0-9]{4}-{0,1}[0-9]{4}-{0,1}[0-9]{4}>" matches 16-digit credit card numbers, whether they contain dashes between each four digits, or not:
1234-5678-9012-3456
1234567890123456
In the above regular expression, "-{0,1}" means "zero or one occurrence of a dash character".
Note about repetition counters:
While both "@" and "{n,m}" allow to match multiple occurrences of the previous character or expression, there is one important difference between these two repetition counters.
With "@", Atlantis performs "lazy matching". "Lazy matching" means that Atlantis will try to find as few occurrences of the previous character or expression as possible.
With the "{n,m}" counter, Atlantis works in the opposite way and performs "greedy matching". "Greedy matching" means that Atlantis will try to find as many occurrences of the previous character or expression as possible.
Let's take an example. At first sight, "be@" and "be{1,}" might seem identical regular expressions. Indeed, both "be@" and "be{1,}" mean the same: "find 'b' followed by at least one occurrence of 'e'". But the difference is that "e@" is completely happy with a single occurrence of "e" even when there are more occurrences in the current document word, while "e{1,}" tries to match as many occurrences of "e" in the current document word as possible. This is why "be@" always matches only the first two letters of "bee" (i.e. "be"), while "be{1,}" matches the entire word "bee".
However, there is one situation when the "{n,m}" counter becomes "lazy": it is when such a counter follows the "?" wildcard (meaning "any character"). Accordingly, the following two regular expressions will match identical texts:
?@
?{1,}
Repetition counters can be applied to
- Individual characters. For example, "a{1,}" matches at least 1 occurrence of "a".
- Character sets. For example, "[!a-z]{3}" matches any 3 non-alphabetic characters.
- Whole groups within round brackets (see below).
Parentheses () and group backreferences \n
Parentheses (or round brackets) can be used to divide the regular expression into shorter expressions (or groups). Each group is assigned an ordinary number starting with the leftmost group. For example, the following regular expression contains two groups:
(<[A-Z].) (<*>)
The group #1 – "<[A-Z]." – is enclosed within the first pair of round brackets. The group #2 – "<*>" – is enclosed within the second pair of round brackets.
You can have up to 9 groups within a regular expression.
Groups can be used in three ways:
- A repetition counter can be applied to a group.
For example, "(<[a-z]@>-){1,}<[a-z]@>" matches a hyphenated compound containing any number of sub-words and hyphens. It would match "non-breaking", "all-or-nothing", "jack-in-the-box", etc. The counter "{1,}" (meaning "at least one occurrence") applies to the entire group "<[a-z]@>-" enclosed in round brackets. "<[a-z]@>-" means "any word followed by a hyphen". By enclosing "<[a-z]@>-" within round brackets and putting a repetition counter "{1,}" after it, we search for any number of occurrences of words followed by a hyphen. - Groups can be reassembled in a different order during the replace operation.
Let's take an example. Let's suppose that you have the following document text:
J. Johnson
B. Miller
C. Bower
Each line in the above text is the initial letter of a first name followed by a surname.
The "Find what" regular expression mentioned above – "(<[A-Z].) (<*>)" – would catch each line from the above sample text. The group #1 of the regular expression – "<[A-Z]." – would catch the initial letter of any of the first names, plus the period following it. The group #2 – "<*>" – would find the associated surname.
Now let's suppose that you need to transpose first name and surname in this way:
Johnson J.
Miller B.
Bower C.
This can be done with the following "Replace with" expression:
\2 \1
The above "Replace with" expression contains two "group backreferences". A "group backreference" is composed of a backslash followed by a group number. Each group backreference represents a specific portion of the text matched by the search, and can be used to reorder and rewrite the found text. In our example, "\2 \1" as replacement pattern is asking Atlantis to reorder the found text so that the string corresponding to group #2 is placed at the start of the line, followed by a space character, plus the string corresponding to group #1. In this way, we achieve our goal, i.e. place the string matched by the second group (surname) before the string matched by the first group (initial). The space character inserted between the surname and the initial is added as a literal character separating group #2 and group #1 in the "Replace with" expression.
A "Replace with" expression need not contain backreferences for all the groups defined in the "Find what" expression. Groups defined in the "Find what" expression can be left out of the "Replace with" pattern, i.e. have no corresponding backreference in it. You will use this method to remove the portion of document text matching the missing backreference(s). Let's take our example above again. Let's suppose that we use "\2" alone instead of "\2 \1" as replacement pattern. The group #1 is no longer referenced in this "Replace with" pattern. Consequently, the text matched by the group #1 expression will not be included in the replacement text, i.e. it will be removed from the original document. In our example, the initial letters representing the first names will be removed from the document text:
Johnson
Miller
Bower
Note that a group backreference can be used recursively within a "Replace with" expression. For example, "(<<[!^p]{1,})" as a "Find what" expression catches email addresses from the following list:
support@company.com
rd@company.com
sales@company.com
"<<" means that the expression catches text at a paragraph start. "[!^p]{1,}" catches as much text in the paragraph as it can, up to, and not including the paragraph end mark.
Now if we associate the "(<<[!^p]{1,})" "Find what" expression to the following "Replace with" expression:
<a href="mailto:\1">\1</a>
we can convert the above list of email addresses into the corresponding HTML code for clickable hyperlinks:
<a href="mailto:support@company.com">support@company.com</a>
<a href="mailto:rd@company.com">rd@company.com</a>
<a href="mailto:sales@company.com">sales@company.com</a> - The group backreferences "\n" can be used within the "Find what" text to identify recurring text.
For example, "(<[a-z]@>) \1" matches repeated words. It would find "really really" in "this is really really bad".
In this expression, group #1 "(<[a-z]@>)" matches any word, and the "\1" backreference matches any other text identical to the text matched by group #1.
Environment delimiters ||
More precise Find & Replace operations can be performed if an "environment" is specified in the search pattern. By "environment", we mean any elements surrounding the text that you are searching for, —preceding and/or following it.
To specify such a restrictive environment within a regular expression, you will use the "|" wildcard (i.e. the "vertical bar"). Any portion of the regular expression that precedes this "|" wildcard will automatically be matched against any text preceding the found item. Any portion of the regular expression that follows a second instance of this "|" wildcard will automatically be matched against any text following the found item. In other words, you can use one or two "|" wildcards to specify what should precede and/or follow the text that you want to find.
Let's take an example. Let's suppose that you have the following list of international phone numbers:
+1-646-222-3333
+49-89-636-48018
+1-541-754-3010
+1-562-756-2233
+49-0711-680-0
+54-11-5530-3250
+44-0844-800-2400
+1-800-233-4175
They all include a country code (1, 44, 49, 54) preceded by "+".
Let's suppose that you need to find all the German phone numbers from the above list but not retrieve the country code "+49" as part of the found items. In other words, you want to find all the German phone numbers in the list, but in their local format (without the country code). So you need to both make sure that the found numbers begin with the "+49" code, and that Atlantis does not include that code in the found items. For this, you need to tell Atlantis that it should search for phone numbers beginning with "+49", but not include "+49" in the search results.
Let's take an example.
The following expression:
+49-[!^p]{1,}
will find any German phone number, including the country code:
+1-646-222-3333
+49-89-636-48018
+1-541-754-3010
+1-562-756-2233
+49-0711-680-0
+54-11-5530-3250
+44-0844-800-2400
+1-800-233-4175
The "+49-" part of the above expression catches the country code plus the following hyphen. "[!^p]{1,}" catches the rest of the phone number (i.e. all the characters up to the paragraph end mark).
Now let's put the "|" wildcard after the "+49-" part of the above regular expression:
+49-|[!^p]{1,}
A search using this new regular expression will catch the following text:
+1-646-222-3333
+49-89-636-48018
+1-541-754-3010
+1-562-756-2233
+49-0711-680-0
+54-11-5530-3250
+44-0844-800-2400
+1-800-233-4175
You can similarly specify a "following environment" in a regular expression. Let's suppose that you want to find any US toll-free phone number (the ones preceded with the "+1" country code) from the following list:
+1-646-222-3333
+49-89-636-48018
+1-541-754-3010 - toll-free
+1-562-756-2233
+49-0711-680-0
+54-11-5530-3250
+44-0844-800-2400
+1-800-233-4175 - toll-free
This expression:
+1-|[!^p]@| - toll-free
will catch the following text from the above list of phone numbers:
+1-646-222-3333
+49-89-636-48018
+1-541-754-3010 - toll-free
+1-562-756-2233
+49-0711-680-0
+54-11-5530-3250
+44-0844-800-2400
+1-800-233-4175 - toll-free
So this expression finds any phone number preceded with "+1-" and followed by " - toll-free", but neither "+1-" nor " - toll-free" are reported as found text.
If you need to specify only a "following environment", you still have to include two instances of the "|" wildcard. But the first instance of "|" should then be placed at the very beginning of the expression. For example, the following expression:
|[!^p]@| - toll-free
will find all the "toll-free" phone numbers (including the country code) from the following list, but it will leave out the part that is outside the boundaries delimited by the "|" wildcard, i.e. the part that matches the pattern or text placed after the second delimiter:
+1-646-222-3333
+49-89-636-48018
+1-541-754-3010 - toll-free
+1-562-756-2233
+49-0711-680-0 - toll-free
+54-11-5530-3250
+44-0844-800-2400 - toll-free
+1-800-233-4175 - toll-free
Escaping wildcards
If you want a wildcard to be treated as an ordinary character in a regular expression, you must tell Atlantis that you mean to use it as a literal character, and not as a wildcard with special meaning. This is done by prefixing the wildcard character with a backslash. For example, "\?" will not match "any character" but an ordinary textual question mark. "\{" will search for an opening curly bracket. "\(*\)" finds any text enclosed between round brackets. "\\" will search for an ordinary textual backslash. Etc.
Special characters in regular expressionsA number of special characters can be used within ordinary search patterns (when the "Use wildcards" option is unchecked in the "Find/Replace" window). Each of these special characters is preceded with "^". For example, you can type "^p" in the "Find what" box to search for paragraph end marks. "^g" will match any picture, "^s" any nonbreaking space. Etc.
All these "^..." special characters available for ordinary searches can also be used in wildcard searches with same meaning. For example, "<^$@e>" matches words ending with "e"; "<^#{2,3}>" matches numbers containing 2 or 3 digits ("78", "112", etc). Special characters can also be used within character sets in regular expressions. For example, "[!^p]" will match any character except a paragraph end mark; "<[^$^#]@>" will match any word containing letters and/or digits.
Examples
A. Finding duplicate paragraphsThe following regular expression will find groups of two neighboring identical paragraphs:
(<<[!^p]{0,}^p)\1
It would find the following pairs of paragraphs:
Bob
Jack
Jack
John
Charlie
Peter
Peter
Chuck
Walk-through:
"<<[!^p]{0,}^p" matches any entire paragraph. Obviously, any paragraph starts with "<<" (meaning "paragraph start"), and is terminated with "^p" (meaning "paragraph end mark"). "[!^p]{0,}" matches all the paragraph contents that lie between the paragraph start and the paragraph end mark. The "{0,} repetition counter means that a paragraph can be blank (i.e. contain nothing but a paragraph end mark). "<<[!^p]{0,}^p" is enclosed within round brackets so that it acts as a group, and it can be referred to through the "\n" wildcard. So the terminating item "\1" of the above regular expression again matches the text already matched by the expression enclosed within round brackets.
To find three neighboring identical paragraphs, you could use this regular expression:
(<<[!^p]{0,}^p)\1\1
The following expression will find any number (2 or more) of neighboring identical paragraphs:
(<<[!^p]{0,}^p)\1{1,}
For example, it would find the following groups of paragraphs:
Bob
Jack
Jack
Jack
Jack
John
Charlie
Peter
Peter
Chuck
Peter
Peter
Peter
Chuck
Now let's suppose that you want to remove the duplicate paragraphs. Simply combine the above "Find what" pattern with the following "Replace with" pattern:
\1
This would replace each found group of paragraphs with the first found paragraph of each such group. In other words, it would remove the redundant paragraphs and keep only the first occurrence of them.
B. Reformatting phone numbersLet's suppose that we have the following list of international phone numbers:
+1-646-222-3333
+49-89-636-48018
+1-541-754-3010
+1-562-756-2233
+49-0711-680-0
+54-11-5530-3250
+44-0844-800-2400
+1-800-233-4175
Each phone number in the above list is preceded with "+" and a country code.
Let's suppose that we need to put the country codes in round brackets and get rid of the "+" signs in order to convert each phone number to the following format:
(1)646-222-3333
This can be done with the following regular expressions:
Find what:
+(^#@)-([!^p]{1,})
Replace with:
(\1)\2
Walk-through:
"+(^#@)" in the "Find what" box catches any country code, including the associated "+" sign. "([!^p]{1,})" catches the phone number, but leaves out the hyphen following the country code. The "+" sign before the country code and the hyphen after the country code are kept outside the round brackets used in the "Find what" expression. In this way, we make sure that the "+" sign and the hyphen after the country code will not be part of the back-reference provided by the grouping of the other elements within round brackets. In this way, when Atlantis uses the text matched by the capturing groups, the "+" sign and the hyphen after the country code will not be included in it. On the other hand, the country code number – "^#@" – and the phone number in the local format – "[!^p]{1,}" – are put within round brackets. This is because these elements will be used to reformat the phone numbers, and need to be associated with group numbers for back-reference in the "Replace with" box.
The "Replace with" expression – "(\1)\2" – means that any country code number and the associated phone number matching the "Find what" expressions "^#@" and "[!^p]{1,}" respectively, will be rearranged so that they follow each other immediately, the country code being placed in first position, and put within round brackets.
So if we use the above "Find what" and "Replace with" patterns on the above original list of phone numbers, we will get this:
(1)646-222-3333
(49)89-636-48018
(1)541-754-3010
(1)562-756-2233
(49)0711-680-0
(54)11-5530-3250
(44)0844-800-2400
(1)800-233-4175
The following paragraph contains a hyperlink (a clickable email address):
Technical support: support@company.com
The hyperlink target address (in our case, the email address) explicitly displays within the paragraph text.
In HTML, this paragraph can be represented through the following code:
<p>Technical support: <a href="mailto:support@company.com">support@company.com</a></p>
But there is an alternative way to compose a hyperlink. Below is a hyperlink to the same email address:
But it does not display the associated email address within the paragraph text. "Technical support" is displayed instead.
Below is the corresponding HTML code:
<p><a href="mailto:support@company.com">Technical support</a></p>
Let's suppose that we have the following document text:
Technical support: support@company.com
Research department: rd@company.com
Sales department: sales@company.com
and we need to convert them into the following HTML code:
<p><a href="mailto:support@company.com">Technical support</a></p>
<p><a href="mailto:rd@company.com">Research department</a></p>
<p><a href="mailto:sales@company.com">Sales department</a></p>
The above HTML code would display like this in a Web browser:
Technical support
Research department
Sales department
This conversion can be done with the following regular expressions:
Find what:
(<<[!^p]@): ([!^p]{1,})
Replace with:
<p><a href="mailto:\2">\1</a></p>
Walk-through:
"(<<[!^p]@)" in the "Find what" pattern catches the description of the email address ("Technical support", "Research department", etc). "([!^p]{1,})" catches the email address itself ("support@company.com", "rd@company.com", etc).
The "Replace with" expression contains the HTML code with two group backreferences. "\2" gets replaced with the email address, and "\1" – with its textual description.
New special characters
New special characters starting with "^" can be now used in the Atlantis Find & Replace dialog, both within regular expressions (when the "Use wildcards" option is checked) and within ordinary search patterns (when the "Use wildcards" option is unchecked). Some of these special characters starting with "^" can be used exclusively in the "Find what" box, some can be used exclusively in the "Replace with" box, and some – in both boxes. See the following tables for details.
Special characters that can be used in both the "Find what" and "Replace with" boxes:
| Character | Description |
| ^nnn | ASCII character. "nnn" is an ASCII code. "nnn" must be greater than 31 and less than 128. Click here for a table of ASCII codes. |
| ^0nnn | ANSII character. "nnn" is an ANSI code. "nnn" must be greater than 31 and less than 256. Click here for a table of ANSI codes. |
| ^unnn | Unicode character. "nnn" is a Unicode code. "nnn" must be greater than 31. Use the "Insert | Symbol..." dialog of Atlantis to determine which decimal codes correspond to characters of interest. |
| ^9 | Tab character. Same as "^t". |
| ^11 | Line break. Same as "^l". |
| ^12 | Page break. Same as "^m". |
| ^13 | Paragraph end mark. Same as "^p". |
| ^14 | Column break. Same as "^n". |
Special characters that can only be used in the "Find what" box:
| Character | Description |
| ^w | White space. Matches one or multiple space characters (any flavor, including non-breaking spaces, Em spaces, and En spaces) or tab characters. |
| ^1 | Picture. Same as "^g". |
| ^2 | Automatic footnote or endnote reference mark. |
| ^L | Any lowercase letter. |
| ^U | Any uppercase letter. |
Special characters that can only be used in the "Replace with" box:
| Character | Description |
| ^& | Current match in the document text corresponding to the search pattern in the "Find what" box. |
| ^c | Clipboard contents. |
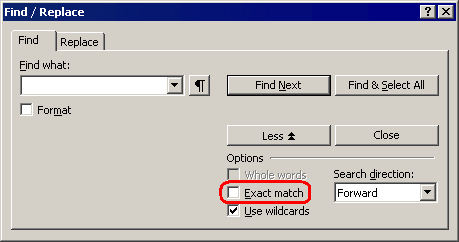
The "Exact match" option
The "Exact match" option in the "Find / Replace" window controls how "sensitive" is the search function of Atlantis:
When the "Exact match" option is unchecked:
- The search is case-insensitive. For example, the regular expression "<[a-z]@>" catches each word in "The head of NASA".
- Characters with diacritical marks and the corresponding base characters are considered as identical. For example, searching for "a" will match "a", "à", "á", "â", "ã", "ä", "å", etc.
- Different flavors of space characters, hyphens, apostrophes, and quotes are considered as identical. For example, searching for a straight quote – " – will also match various smart quotes:
“”«»„
When the "Exact match" option is checked:
- The search is case-sensitive. For example, the regular expression "<[a-z]@>" catches only "head" and "of" in "The head of NASA".
- Characters with diacritical marks and the corresponding base characters are considered as different characters. For example, searching for "a" will not match "à", "á", "â", "ã", "ä", "å", etc.
- Different flavors of space characters, hyphens, apostrophes, and quotes are considered as different characters. For example, searching for a straight quote – " – will match only straight quotes.
"Inverted" search
Atlantis offers plenty of options to search for certain text or formatting. But in some cases, you might need to do the opposite thing – search for document fragments not containing certain text or formatting.
Let's take an example. Let's suppose that your document contains paragraphs with different alignment:
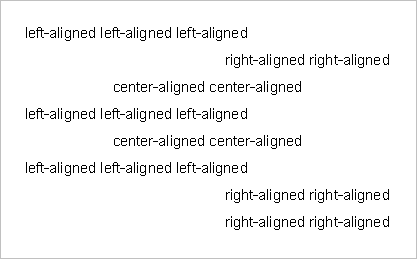
Let's suppose that you want to find all the paragraphs with any alignment except left. Here is how this can be done:
As a first step, you need to find all left-aligned paragraphs in the document. To do so, leave the "Find what" box blank in the "Find / Replace" window, and check the "Format" box under the "Find what" box:
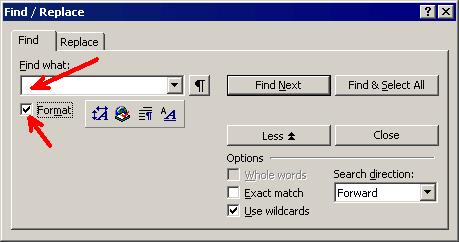
Then click the "Paragraph format" button below the "Find what" box:
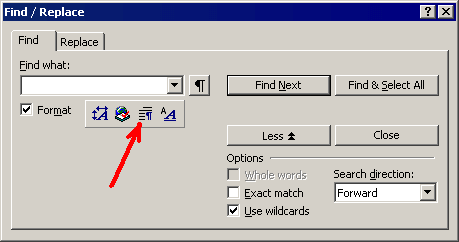
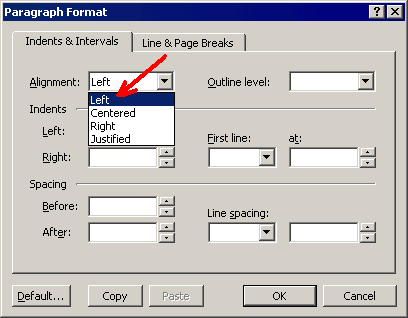
and choose "Left" in the "Alignment" drop-down list:
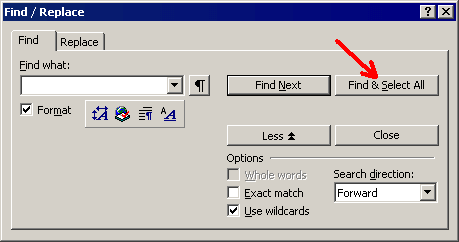
When these options are set, press the "Find & Select All" button in the "Find / Replace" window:
Atlantis will select all left-aligned paragraphs in the document:

Finally, press Ctrl+K,A, the default hot key for the "Invert selection" command. This command deselects selected fragments, and selects fragments which are currently non-selected. After pressing Ctrl+K,A, you will get this:

All the non-left-aligned paragraphs in the document are selected, and you can perform various actions on the selection (apply a paragraph style, change paragraph alignment, etc).
See more release notes.



