|

Recherches avec expressions régulièresCaractères génériques et expressions régulièresLes expressions régulières (on utilise parfois la contraction anglaise "regex") peuvent être utilisées pour constituer des filtres de recherche/remplacement extrêmement puissants et précis permettant de trouver des fragments de texte spécifiques, et, éventuellement, de les remplacer par un texte différent et/ou une mise en forme différente. Une expression régulière peut contenir :
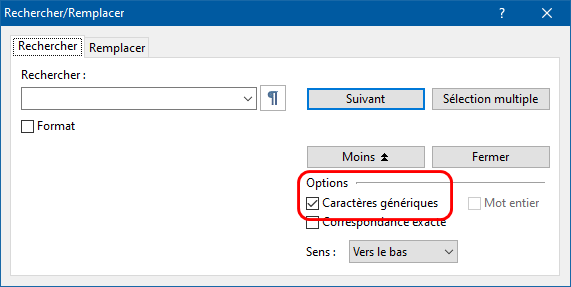
Un caractère générique est un caractère ou symbole ayant une signification spéciale pour la fonction de recherche/remplacement : à lui tout seul, il peut être utilisé pour représenter des caractères ordinaires, des catégories de caractères, une plage alphabétique de caractères, des groupes de caractères, ou des marques de mise en forme. Pour faire des recherches utilisant des expressions régulières, la boîte de dialogue Rechercher/Remplacer comprend l’option Caractères génériques :
Quand l'option Caractères génériques est active, les éléments de recherche/remplacement que vous saisissez dans les cases Rechercher et Remplacer par sont automatiquement traités comme étant des expressions régulières. Quand l'option Caractères génériques est inactive, les éléments de recherche/remplacement que vous saisissez dans les cases Rechercher et Remplacer par sont automatiquement traités comme étant des caractères littéraux sans signification spéciale, et Atlantis effectue une recherche ordinaire. Notez que les options Caractères génériques et Mot entier sont mutuellement exclusives : vous ne pourrez pas activer les deux à la fois ; ce sera ou l'une ou l'autre. En d'autres termes, vous ne pourrez utiliser l'option Mot entier que dans des recherches ordinaires ; l'option Mot entier sera indisponible lorsque vous effectuerez des recherches avec expressions régulières. Les expressions régulières vous offrent d'autres moyens de rechercher des "mots entiers".
Les caractères génériques dans Atlantis? et *? (le point d’interrogation) est le caractère générique le plus général. Il sert à représenter n’importe quel caractère pris individuellement, littéral ou non : lettre de l’alphabet, signe de ponctuation, espace, marque de fin de paragraphe, et même image. En bref, tout élément distinct pouvant entrer dans la composition d'un document. Par exemple, l’expression l?s (avec l’option Correspondance exacte activée) permettrait de trouver des séquences de caractères comme “las”, “les”, “lès” “lis”, ou “lys”, etc. L'expression b?lle (avec l’option Correspondance exacte désactivée) permettrait de trouver des séquences de caractères comme “balle”, “belle”, “bille”, “bullé”, etc. * (l’astérisque) sert à représenter n’importe quelle chaîne de caractères, littéraux ou non : lettres de l’alphabet, signes de ponctuation, espaces, marques de fin de paragraphe, images, et même des chaînes de caractères composées de blancs. En bref, toute association d'éléments pouvant entrer dans la composition d'un document. Par exemple, l’expression l*t permettrait de trouver des mots comme “ledit” “ligot”, “livet”, “loquet”, “lysat”, “l'aligot”, ou des fragments de texte beaucoup plus long comme “les membres de la famille humaine et”. Etc. Dans ce genre de recherche, l’astérisque couvre tout ce qui peut se trouver entre les caractères spécifiés dans l’expression régulière. Mais attention ! Il y a des exceptions et des cas particuliers à prendre en considération :
< et >< sert à représenter le début d’un mot. Par exemple, l’expression <comp permettrait de trouver “comp” au début de mots comme “compact”, “compétition”, “comptage”, “compulsion”, mais laisserait de côté des mots comme “accompli” “biocompatible”, ou “surcomposé”, bien qu’ils comprennent la chaîne de caractères “comp” eux aussi. > sert à représenter la fin d’un mot. Par exemple, l’expression ter> permettrait de trouver “ter” à la fin de mots comme “abriter”, “adopter”, “breveter”, “susciter”, mais laisserait de côté des mots comme “atterrer” “chatterton”, ou “interpoler”, bien qu’ils comprennent la chaîne de caractères “ter” eux aussi. << et ^p<< sert à représenter le début d’un paragraphe. Par exemple, l’expression <<1. permettrait de trouver “1.” au début, mais pas au milieu, ni à la fin d’un paragraphe. Notez que << peut s’utiliser conjointement avec <. Par exemple, l’expression <<<*> permettrait de trouver n’importe quel mot situé au début d’un paragraphe. <<<comp permettrait de trouver n’importe quel mot situé au début d’un paragraphe, et commençant par “comp”. ^p sert à représenter la fin d’un paragraphe. Par exemple, l’expression charité^p permettrait de trouver “charité” à la fin, mais pas au début, ni au milieu d’un paragraphe. Les ensembles de caractères […] et [!…]Les crochets […] servent à représenter des ensembles de caractères. Chacun des caractères spécifiés sera obligatoirement considéré individuellement, et à tour de rôle dans la recherche. En d'autres termes, vous demandez à Atlantis de rechercher tel caractère ou tel autre, ou tel autre encore. Etc. Par exemple, l’expression [aei] représente les caractères “a”, “e”, et “i”, pris individuellement. Aussi, l’expression l[aei]s permettrait de trouver des mots comme “las”, “les”, “lès” “lis”, mais pas “leasing”. Notez que dans une expression régulière, aei, employé sans crochets, permettrait de trouver toute succession littérale des caractères “aei” dans un document. Ainsi, aei, utilisé dans une expression régulière, vous permettrait, par exemple, de trouver “aei” dans "élaeis” : élaeis Notez aussi que le trait d’union doit être précédé d’une barre oblique inverse [\-] si vous voulez le rechercher en tant que caractère ordinaire dans une expression régulière placée entre crochets. Voyez plus bas la rubrique Valeur littérale pour les caractères génériques pour plus de précisions. Il est possible de spécifier des plages de caractères à l’intérieur des expressions régulières définissant un ensemble de caractères. Cela se fait à l’aide d’un trait d’union joignant les caractères délimitant la plage. Par exemple, l’expression [a-z] représente tout caractère alphabétique compris entre “a” et “z”. L’expression [d-s] représenterait tout caractère alphabétique compris entre “d” et “s”. Etc. Notez que ces plages de caractères doivent être exprimées dans un ordre ascendant. Vous pourrez spécifier [a-z], mais pas [z-a]. Il est même possible de spécifier à la fois des plages de caractères et des caractères particuliers à l’intérieur d’une même plage de caractères. Par exemple, l’expression [b-df-hj-np-tv-xz] représente n’importe quelle consonne. Cette expression contient 5 plages de caractères différentes : de “b” à “d”, de “f” à “h”, de “j” à “n”, de “p” à “t”, et de “v” à “x”. Elle contient aussi 1 caractère particulier “z”. Enfin, il est possible de créer des plages de caractères couvrant tout ce qui n’est pas défini expressément dans l’ensemble de caractères spécifié. On utilise pour cela le symbole ! (point d'exclamation) que l’on place immédiatement après le crochet ouvrant [ de l’ensemble de caractères. En d’autres termes, le symbole ! placé au début d’un ensemble de caractères exclut de la recherche les caractères ou plages de caractères qui le suivent. Par exemple, l’expression [!a-e] couvre tout caractère à l’exception des caractères spécifiés dans la plage “a-e”, c’est-à-dire les caractères “a”, “b”, “c”, “d”, “e”.
Les quantificateurs @ et {n,m}@ et {n,m} servent tous deux à représenter combien d’occurrences du caractère ou de l’expression qui les précède doivent être recherchées. @ sert à représenter une ou plusieurs occurrences du caractère ou de l’expression le précédant. Par exemple, l’expression co@l vous permettrait de trouver des mots comme “col” et “cool”. {n,m} peut être utilisé de trois manières différentes :
Notez que vous pouvez donner la valeur 0 (zéro) à n dans le quantificateur {n,m}. Cela signifiera que zéro occurrence du caractère ou de l’expression précédant le quantificateur est envisagée. Par exemple, l’expression <[0-9]{4}[\- ]{0,1}[0-9]{4}[\- ]{0,1}[0-9]{4}[\- ]{0,1}[0-9]{4}> vous permettrait de trouver tout numéro de carte de crédit à 16 chiffres, que ces numéros contiennent, ou pas, des traits d’union ou des caractères espaces séparateurs :
Dans l’expression régulière ci-dessus, [\- ]{0,1} représente “zéro ou une occurrence d’un trait d’union ou d’un caractère espace”.
Les parenthèses (…) et numéros de groupes \nQuand elles sont utilisées dans un filtre de recherche à l’intérieur d’une expression régulière, les parenthèses ont, elles aussi, une signification spéciale pour Atlantis : elles lui indiquent que les éléments inclus à l’intérieur de parenthèses sont à considérer comme des groupes particuliers auxquels il pourra être fait référence par la suite dans le schéma de recherche/remplacement. Un numéro d’ordre de 1 à 9 est automatiquement attribué à chacun des groupes ainsi défini par les parenthèses, la numérotation se faisant naturellement de gauche à droite (le nombre maximum de groupes que l’on peut ainsi définir est donc de 9). Prenons un exemple. L’expression régulière suivante contient 2 groupes entre parenthèses : (<[A-Z].) (<*>) Les éléments inclus à l’intérieur des premières parenthèses forment le premier groupe de cette expression régulière. Le numéro “1” est automatiquement attribué à ce groupe. Les éléments inclus à l’intérieur des deuxièmes parenthèses forment le deuxième groupe de cette même expression régulière. Le numéro “2” est automatiquement attribué à ce groupe. De tels groupes peuvent être utilisés de 3 manières différentes : A. Les groupes d'une expression régulière peuvent être associés à un quantificateur. Par exemple, l’expression régulière (<[^$']{1,}>-){1,}<[^$']{1,}> vous permettrait de trouver tout mot composé contenant deux ou plusieurs mots séparés par un trait d’union, et comprenant éventuellement une élision marquée par une apostrophe (comme dans “s’entre-dévorer”). Cette expression trouverait par exemple “A-Z”, “a-z”, “abaisse-langues”, “accroche-cœurs”, “allume-cigares”, “amuse-gueule”, “après-rasage”, “attrape-nigauds”, “brise-fer”, “brûle-parfum”, “cache-pot”, “chasse-neige”, “ci-dessous”, “coupe-jarret”, “essuie-main”, “est-sud-est”, “faire-valoir”, “garde-barrière”, “gâte-sauce”, “hache-légume”, “je-m’en-fichisme”, “jusqu’au-boutiste”, “laisser-aller”, “laisser-faire”, “laissez-passer”, “lance-grenade”, “marie-couche-toi-là”, “monte-charge”, “oto-rhino-laryngologiste”, “pare-balle”, “passe-crassane”, “pet-en-l’air”, “pince-sans-rire”, “porte-avion”, “prie-Dieu”, “quasi-ignorance”, “quatre-vingt-dix-septième”, “qu’en-dira-t-on”, “s’entre-dévorer”, “sauve-qui-peut”, “savoir-faire”, “savoir-vivre”, “suivez-moi-jeune-homme”, “trompe-l’œil”, “va-comme-je-te-pousse”, etc. Analyse : Il y a 1 groupe défini par des parenthèses dans l’expression régulière ci-dessus. Ce groupe (<[^$']{1,}>-) représente “tout mot constitué d’une ou plusieurs lettres de l’alphabet et éventuellement d’une ou plusieurs apostrophes (marquant l’élision), et suivi d’un trait d’union”. Ce même groupe est associé à un quantificateur {1,} signifiant que le type de texte correspondant à ce groupe pourra éventuellement être présent une ou plusieurs fois. Ceci permet de couvrir les mots composés de plusieurs mots et comprenant plusieurs traits d’union (comme “quatre-vingt-dix-septième” ou “va-comme-je-te-pousse”, par exemple). La suite de l’expression régulière <[^$']{1,}> représente elle aussi “tout mot constitué d’une ou plusieurs lettres de l’alphabet et éventuellement d’une ou plusieurs apostrophes (marquant l’élision)”. Mais le trait d’union présent dans le premier groupe a été exclu de cette portion de l’expression régulière : en effet, le mot terminant un mot composé ne peut pas être suivi immédiatement d’un trait d’union. B. En utilisant les numéros de ces groupes, on peut demander à Atlantis de disposer dans un ordre différent les textes qui correspondent à ces groupes. Prenons un exemple. Supposons que nous ayons le texte suivant :
Chacune des lignes ci-dessus est composée de l’initiale d’un prénom, suivie d’un nom de famille. Si nous utilisons le filtre de recherche mentionné plus haut – (<[A-Z].) (<*>) –, il retiendra chacune de ces lignes dans sa totalité. Chaque ensemble “initiale de prénom+point” correspondra parfaitement au groupe de recherche 1 – <[A-Z]. –, tandis que les lettres composant chacun des noms correspondront parfaitement au groupe de recherche 2 – <*> –. L’espace séparant les 2 groupes dans le filtre de recherche correspondra à l’espace séparant chacun des prénoms du nom de famille dans le document. Supposons maintenant que nous voulions transposer prénoms et noms de façon à obtenir ceci :
Cela peut être fait très rapidement avec le schéma de recherche/remplacement suivant : Rechercher : (<[A-Z].) (<*>) Remplacer par : \2 \1 Ce schéma de remplacement contient deux numéros de groupe, séparés par un caractère espace. Ces numéros de groupe peuvent être placés dans un schéma de recherche/remplacement, et sont toujours constitués d’une barre inverse oblique \, immédiatement suivie d’un numéro d’ordre faisant référence au numéro automatiquement attribué à chacun des groupes éventuellement présents dans le filtre de recherche. De cette manière, chacun de ces numéros de groupe représente à lui tout seul le texte trouvé grâce à la portion d’expression régulière contenue dans le groupe de recherche de même numéro. Dans l’exemple ci-dessus, (<[A-Z].) (<*>) trouvera tout d’abord “A. Joly”. Le groupe 1 aura trouvé “A.”; le groupe 2 “Joly”. Dans le schéma de remplacement, \2 représentera donc “Joly”, et \1 représentera “A.” Il est donc possible de réordonner le texte correspondant aux groupes 1 et 2 de façon que le texte du groupe 2 précède celui du groupe 1, avec un caractère espace intercalaire. C’est ce schéma de remplacement qu’exprime \2 \1. Notez qu’un schéma de remplacement saisi dans la zone Remplacer par n’a pas besoin de contenir une référence à tous les groupes prédéfinis dans la zone Remplacer. Omettre de faire référence dans la zone Remplacer par à un ou plusieurs groupes prédéfinis dans la zone Rechercher pourra vous permettre tout simplement de supprimer le texte correspondant dans le document. Reprenons l’exemple ci-dessus. Supposons qu’au lieu d’utiliser le schéma de remplacement complet \2 \1, nous utilisions simplement \2. De ce fait, le texte correspondant au groupe 1 ne sera pas inclus dans le texte de remplacement. En d’autres termes, le texte correspondant au groupe 1 (c’est-à-dire l’ensemble “prénom+point”) sera retiré du document, et seul le texte correspondant au groupe 2 sera substitué au texte original. Nous obtiendrons donc ceci :
Notez qu’un numéro de groupe peut être utilisé de manière récursive à l’intérieur d’un même schéma de remplacement. Prenons un exemple. Le filtre de recherche (<<[!^p]{1,}) vous permettrait de trouver les adresses email figurant dans la liste suivante :
<< signifie que cette expression vise un texte se trouvant au début d’un paragraphe. [!^p]{1,} signifie que le texte visé est tout le texte du paragraphe jusqu’à la marque de fin de paragraphe, mais sans inclure cette dernière. La mise entre parenthèses de l’expression (<<[!^p]{1,}) signifie que le texte trouvé sera considéré comme un groupe auquel on peut faire référence de manière répétitive (récursive). Associons maintenant le filtre de recherche (<<[!^p]{1,}) au schéma de remplacement suivant inséré dans la zone Remplacer par : <a href="mailto:\1">\1</a> Si nous appuyons sur le bouton Remplacer tout, nous obtiendrons le code HTML correspondant à des adresses email cliquables dans la fenêtre d’un navigateur Internet : <a href="mailto:support@compagnie.com">support@compagnie.com</a> <a href="mailto:R&D@compagnie.com">R&D@compagnie.com</a> <a href="mailto:ventes@compagnie.com">ventes@compagnie.com</a> Que s’est-il passé ? Atlantis a trouvé successivement chacune des adresses email, et a substitué par deux fois chacune d’entre elle au numéro de groupe (\1) la représentant dans le schéma de remplacement : <a href="mailto:\1">\1</a> C. Les numéros de groupe \n peuvent être utilisés à l’intérieur même d’un filtre de recherche afin d’identifier tout texte récurrent. Par exemple, (<[a-z]@>) \1 pourrait servir à détecter des doublons comme, par exemple, “très très” dans “J’en avais très très envie !” Dans ce filtre de recherche, le groupe 1 (<[a-z]@>) a pour pendant “n’importe quel mot” du document, et le numéro de groupe \1 a pour pendant tout autre mot identique à celui déjà trouvé par le groupe 1. Le filtre de recherche signalera donc toute répétition de mots qui se suivent. Dans notre exemple, (<[a-z]@>) trouvera la première occurrence de “très”, tandis que \1 trouvera tout mot identique à celui que vient de trouver (<[a-z]@>), c’est-à-dire une répétition du mot “très” : “J’en avais très très envie !”
Les délimiteurs environnementaux |…|Vous réaliserez des opérations de recherche/remplacement plus précises si vous spécifiez un “environnement” dans le filtre de recherche. Par "environnement", on entend tous éléments susceptibles de se trouver dans l’environnement du texte recherché, soit q’ils le précèdent, soit qu’ils le suivent. Pour préciser un tel environnement restrictif dans une expression régulière, vous utiliserez le symbole | (c’est-à-dire la “barre verticale”). Atlantis recherchera alors automatiquement une concordance entre toute portion de l’expression régulière placée avant le caractère générique | et le texte précédant le fragment de document trouvé ; ainsi qu’entre toute portion de l’expression régulière placée après le caractère générique | et le texte suivant le fragment de document trouvé. En d’autre termes, vous pouvez utiliser un ou deux caractères génériques | pour préciser ce qui devra précéder et/ou suivre le texte recherché. Prenons un exemple. Supposons que vous ayez la liste suivante, constituée de numéros de téléphone internationaux :
Ces numéros comprennent tous un code de pays (1, 44, 49, ou 54) précédé par le signe “+”. Supposons que vous deviez sélectionner tout numéro de téléphone allemand dans cette liste sans son code de pays. Il faut vous assurer que les numéros trouvés commenceront bien par “+49”, mais que la sélection qui en sera faite ne comprendra pas le code “+49”. L’expression régulière +49-[!^p]{1,} sélectionnerait tout numéro de téléphone allemand avec son code de pays :
Dans l’expression régulière ci-dessus, +49- sera naturellement mis en correspondance avec le code du pays, suivi d’un trait d’union. [!^p]{1,} sera mis en correspondance avec le numéro de téléphone proprement dit, c’est-à-dire avec l’ensemble des caractères placés après “+49-”, jusqu’à la marque de fin de paragraphe non comprise. Introduisons maintenant un délimiteur environnemental | après +49- dans l’expression régulière ci-dessus. Nous obtenons ceci : +49-|[!^p]{1,} Cette nouvelle expression sélectionnera les numéros de téléphone allemands sans le code de pays :
Dans l’exemple précédent, nous avons spécifié un environnement précédant le texte recherché. Mais vous pourrez vouloir spécifier également un environnement suivant le texte recherché. Supposons que vous vouliez trouver dans la liste ci-dessous tout numéro de téléphone américain à appel gratuit (ceux qui sont précédés du code “+1” et suivis de l'indication "-appel gratuit") :
L’expression régulière +1-|[!^p]@|-appel gratuit vous permettra de sélectionner les numéros concernés :
Analyse : Dans l’expression régulière ci-dessus, +1- se trouve à gauche du premier délimiteur environnemental |. Cette partie de l’expression permet à Atlantis d’identifier les numéros américains visés. -appel gratuit, quant à lui, se trouve à droite du deuxième délimiteur environnemental |. Cette partie de l’expression permet à Atlantis d’identifier les numéros dont l’appel est gratuit. Mais ces “environnements” ne font pas partie de la sélection opérée par Atlantis. Ils ne lui servent qu’à localiser le texte recherché avec grande précision. Il vous arrivera de vouloir spécifier uniquement l’environnement suivant le texte recherché. Vous devrez quand même utiliser deux délimiteurs environnementaux |, mais le premier d’entre eux devra se trouver au tout début de l’expression régulière. Par exemple, l’expression |[!^p]@|-appel gratuit trouverait tout numéro de téléphone à appel gratuit :
Analyse : Dans l’expression régulière ci-dessus, -appel gratuit est situé après le second délimiteur environnemental |. Ce texte servira à localiser les numéros à appel gratuit, mais seule la portion de l’expression régulière située entre les deux délimiteurs environnementaux |[!^p]@| sera effectivement mise en correspondance avec le texte du document. En d’autres termes, le texte -appel gratuit ne fera pas partie de la sélection opérée par Atlantis. Valeur littérale pour les caractères génériquesÉtant donné que les caractères génériques ont une signification particulière dans tout ensemble de caractères défini à l’intérieur d’une expression régulière, Atlantis ne peut évidemment pas les prendre dans leur sens littéral quand ils y sont utilisés. Par conséquent, si vous voulez inclure un caractère générique dans une expression régulière en tant que caractère ordinaire, il vous faut neutraliser la signification spéciale qu’il a aux yeux d’Atlantis. Ça se fait en plaçant une barre oblique inverse \ devant le caractère. Par exemple, l’expression [\?] vous permettrait de rechercher tout point d’interrogation ordinaire. La barre oblique inverse \ ne peut pas non plus être recherchée telle quelle à travers une expression régulière. Il vous faut également neutraliser la signification spéciale qu’elle a aux yeux d’Atlantis. Ça se fait en plaçant une première barre oblique inverse \ devant le caractère \. Par exemple, l’expression régulière 1\\2 vous permettrait de rechercher la chaîne de caractères "1\2" : la barre oblique inverse ordinaire étant représentée par \\ dans l’expression régulière. Vous procéderez de même pour rechercher tout caractère ordinaire ayant une signification non littérale dans une expression régulière. Ce sera le cas, par exemple, des caractères suivants qui devront être précédés d'une barre oblique inverse si vous voulez les rechercher en tant que caractères ordinaires dans une recherche avec expression régulière : \@ recherchera le “a” commercial @ \* recherchera le caractère étoile (astérisque) * \( recherchera la parenthèse ouvrante ( \) recherchera la parenthèse fermante ) \{ recherchera l’accolade ouvrante { \} recherchera l’accolade fermante } \[ recherchera le crochet ouvrant [ \] recherchera le crochet fermant ] \\ recherchera la barre oblique inverse \ Etc. Comme nous l’avons vu plus haut, le trait d’union sert à délimiter des plages de caractères à l’intérieur des crochets représentant eux-mêmes des ensembles de caractères : le trait d'union a donc une signification spéciale pour Atlantis quand il est placé entre crochets dans une expression régulière. Par exemple, [g-m] représente la plage de caractères allant de la lettre “g” à la lettre “m”. Aussi, si vous voulez faire une recherche de trait d’union en tant que caractère ordinaire sans signification spéciale pour Atlantis, et que cette recherche est faite entre les crochets d’une expression régulière, il faut le faire précéder d’une barre oblique inverse \. Par exemple, [g-m\-] rechercherait tout caractère allant de la lettre “g” à la lettre “m”, et suivi d’un trait d’union ordinaire.
Expressions régulières et caractères spéciauxUn certain nombre de caractères spéciaux peuvent être utilisés à l’intérieur de filtres de recherche ordinaires (c’est-à-dire quand l’option de recherche avec Caractères génériques est inactive). Chacun de ces caractères spéciaux est précédé du symbole ^. Par exemple, vous pouvez saisir ^p dans la zone Rechercher pour chercher toute marque de fin de paragraphe, ^g pour chercher toute image, ^s pour chercher tout caractère espace insécable. Etc. Mais tous ces caractères spéciaux précédés du symbole ^ peuvent également être utilisés dans des recherches avec expressions régulières (c’est-à-dire quand l’option de recherche avec Caractères génériques est active). Par exemple, <^$@e> trouverait tout mot se terminant par “e” ; <^#{2,3}> trouverait tout nombre de 2 ou 3 chiffres (“78”, “112”, etc.) Les caractères spéciaux précédés du symbole ^ peuvent même être utilisés à l’intérieur de plages de caractères dans des expressions régulières. Par exemple, [!^p] trouverait n’importe quel caractère, à l’exception des marques de fin de paragraphe ; <[^$^#]@> trouverait tout mot comprenant des lettres et/ou des chiffres. En résumé, les caractères spéciaux précédés du symbole ^ ont toujours la même signification pour Atlantis, qu’ils soient utilisés dans le cadre d’une recherche ordinaire, ou d’une recherche où l’option Caractères génériques est activée (c’est-à-dire dans le cadre d’une recherche avec expressions régulières). Les boutons
Exemples d'utilisation des expressions régulièresTrouver des paragraphes dupliquésL’expression régulière (<<[!^p]{0,}^p)\1 vous permettrait de sélectionner les paragraphes en double dans la liste ci-dessous :
Analyse : <<[!^p]{0,}^p correspond à tout paragraphe : << signifie “début de paragraphe”, et ^p signifie “fin de paragraphe” ; [!^p]{0,} représente tout ce qui pourra se trouver entre le début du paragraphe et la marque de fin de paragraphe. Le quantificateur {0,} signifie qu’un paragraphe pourra être vide (c’est-à-dire n’être constitué que d’une marque de fin de paragraphe). <<[!^p]{0,}^p est placé entre parenthèses pour signaler à Atlantis qu’il devra le considérer comme un groupe. Ce groupe fait l’objet d’un rappel immédiat grâce à son numéro \1. (<<[!^p]{0,}^p)\1 sélectionnera ainsi tout paragraphe trouvé suivi d’un paragraphe identique, et donc tout ensemble de deux paragraphes identiques. L’expression régulière (<<[!^p]{0,}^p)\1\1 vous permettrait de sélectionner des paragraphes non plus doublés, mais triplés (notez l’utilisation de deux renvois au groupe 1 : 1+1+1=3). Quant à elle, l’expression régulière (<<[!^p]{0,}^p)\1{1,} vous permettrait de sélectionner n’importe quel ensemble de paragraphes dupliqués une ou plusieurs fois. Comme, par exemple, les paragraphes dupliqués dans la liste ci-dessous :
Supposons que vous vouliez supprimer les paragraphes qui doublonnent. Il vous suffit de combiner le filtre de recherche ci-dessus avec le schéma de remplacement suivant : \1 Une telle opération de recherche/remplacement remplacerait chaque ensemble de paragraphes dupliqués par le premier d’entre eux. En d’autres termes, Atlantis supprimerait les paragraphes qui doublonnent, et ne garderait que le premier d’entre eux. Changer le format de numéros de téléphoneSupposons que vous ayez une liste de numéros de téléphone internationaux comme celle-ci :
Chacun de ces numéros de téléphone est précédé d’un signe “+”, suivi d’un code de pays. Supposons que vous vouliez supprimer les signes “+”, et mettre les codes de pays entre parenthèses pour aboutir au format suivant : (1)646-222-3333 C’est possible avec le schéma de recherche/remplacement suivant : Rechercher : +(^#@)-([!^p]{1,}) Remplacer par : (\1)\2 Analyse : La recherche de +(^#@) permet de trouver le code de pays, ainsi que le “signe+” qui précède. Quant à ([!^p]{1,}), il permettra de sélectionner le numéro de téléphone associé, tout en ignorant le trait d’union qui précède. Le signe + et le trait d’union qui précède le numéro de téléphone sont ainsi placés hors des parenthèses utilisées dans l’expression placée dans la zone Rechercher. De cette manière, on s’assure que le signe + et le trait d’union qui précède le numéro de téléphone ne seront pas inclus dans les groupes définis par les parenthèses, et donc seront exclus de toute référence à ces groupes. Par contre, le code de pays – ^#@ –, puis le numéro de téléphone dans son format local – [!^p]{1,} –, sont mis entre parenthèses. On pourra ainsi faire référence à ces éléments dans la zone Remplacer par à travers leurs numéros de groupe, et utiliser ces derniers pour changer le format des numéros de téléphone originaux. L’expression régulière utilisée dans la zone Remplacer par – (\1)\2 – signifie que tout code de pays et numéro de téléphone associé correspondant au schéma ^#@ et [!^p]{1,} respectivement, seront réarrangés de façon à ce qu’ils se suivent sans interruption, le code de pays étant placé en premier, et mis entre parenthèses. Donc, si nous appliquons le schéma de recherche/remplacement ci-dessus à la liste de numéros de téléphone originale, nous obtiendrons ceci :
Convertir les adresses email en hyperliensLe paragraphe suivant contient une adresses email cliquable (hyperlien) : Support technique : support@compagnie.com L’adresse de destination de cet hyperlien s’affiche en clair. En code HTML, le paragraphe ci-dessus peut s’écrire comme ceci : <p>Support technique& ;: <a href="mailto:support@compagnie.com">support@compagnie.com</a></p> Il existe cependant une autre manière de présenter un hyperlien. En voici un exemple, avec la même adresse de destination que précédemment : Support technique Ce type d'hyperlien n’affiche pas l’adresse associée de manière visible. Le texte affiché (“Support technique”) est différent de l’adresse associée. En code HTML, le paragraphe ci-dessus peut s’écrire comme ceci : <p><a href="mailto:support@compagnie.com">Support technique</a></p> Supposons maintenant que vous ayez la liste suivante d’adresses email :
Et que vous vouliez la convertir au format suivant :
Le code HTML correspondant devra se présenter comme ceci :
Il vous faut donc convertir le texte de la liste initiale pour qu’il se présente comme ci-dessus. Cette conversion pourra se faire en utilisant le schéma de recherche/remplacement suivant : Rechercher : (<<[!^p]@): ([!^p]{1,}) Remplacer par : <p><a href="mailto:\2">\1</a></p> Analyse : Dans la zone Rechercher, (<<[!^p]@) permet de trouver la description correspondant à l’adresse email (“Support technique”, “Recherche & Développement”, “Service après-vente”). ([!^p]{1,}) trouve l’adresse email elle-même (“support@compagnie.com”, “R&D@compagnie.com”, “SAV@compagnie.com”). La zone Remplacer par contient le code HTML représentant toute adresse email, plus 2 numéros de groupe, \2, et \1, dans cet ordre réarrangé. \2 sera automatiquement remplacé par l’adresse email trouvée, et \1, par la description textuelle qui lui est associée. Recherche d'adresses courrielLes expressions régulières suivantes vous permettrons de rechercher des adresses courriel dans vos documents, et éventuellement de gérer des listes de diffusion électronique. il vous suffira de les coller dans la case Rechercher du volet Rechercher/Remplacer du pupitre de commande d'Atlantis, ou de la boîte de dialogue standard Rechercher/Remplacer.
Encore plus d'exemples d'utilisation des expressions régulièresNous avons constitué une collection de schémas (ou “filtres”) de recherche/remplacement utilisant les expressions régulières, et qui marchent dans Atlantis. Ces exemples sont rassemblés dans un document nommé "Traitement de texte Atlantis - Exemples d'utilisation des expressions regulieres.rtf". Il est disponible en téléchargement libre sur le site français d'Atlantis à la page Exemples & modèles de documents. Cliquez sur le lien ci-après pour télécharger ce document immédiatement : Traitement de texte Atlantis - Exemples d'utilisation des expressions regulieres.rtf. Pour ceux d'entre vous qui ont des besoins encore plus poussés concernant les opérations de recherche/remplacement utilisant les expressions régulières, nous avons rassemblé quelques exemples supplémentaires dans un document nommé "Recherches complexes de mises en forme.rtf". Il est disponible en téléchargement libre sur le site français d'Atlantis à la même page Exemples & modèles de documents. Cliquez sur le lien ci-après pour télécharger ce document immédiatement : Traitement de texte Atlantis - Recherches complexes de mises en forme.rtf. Voyez aussi… | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 situés en regard des zones de saisie Rechercher ou Remplacer par de la boîte de dialogue Rechercher/Remplacer vous permettent d'insérer les caractères spéciaux dédiés avec beaucoup de facilité. Cependant, vous pourrez vouloir les saisir directement depuis votre clavier. Vous en trouverez la liste complète ci-dessous. Deux remarques préliminaires :
situés en regard des zones de saisie Rechercher ou Remplacer par de la boîte de dialogue Rechercher/Remplacer vous permettent d'insérer les caractères spéciaux dédiés avec beaucoup de facilité. Cependant, vous pourrez vouloir les saisir directement depuis votre clavier. Vous en trouverez la liste complète ci-dessous. Deux remarques préliminaires :| |