Hi,
For those of you interested in the regex capabilities of Atlantis Word Processor, here is an updated version of our “Atlantis Regex Library”. This document has been completely overhauled. It now includes detailed “Walk-through” explanations about the regex patterns used in the examples. The regex patterns themselves have been improved whenever possible.
Please, have a look at the attached document, and don’t hesitate to ask questions if there are things you don’t understand, or if you have searches you’d like to have help about.
Cheers,
Robert
Atlantis Word Processor - Examples Of Regex Patterns II
Atlantis Word Processor - Examples Of Regex Patterns II
- Attachments
-
- Atlantis Word Processor - Examples Of Regex Search Patterns II.docx
- (149.69 KiB) Downloaded 1667 times
Great idea!
It is strange to me that no one has commented on this. I downloaded the updated Regex Library a few days ago, but I have not had a chance to investigate it.
If this does what I think it does, it is exactly what I have needed for years. For example, I do a lot of file conversions in working with screenplays, and a perennial problem is how to get rid of the confounded page numbers at the top right of the page (left over from the PDF-to-text conversion). The page number is always preceded by numerous spaces on the same line. It is too cumbersome to do a traditional search-and-replace for every number (believe me, I know; I have done it). But it looks as if using the Regex function will let me automate this kind of thing.
If this does what I think it does, it is exactly what I have needed for years. For example, I do a lot of file conversions in working with screenplays, and a perennial problem is how to get rid of the confounded page numbers at the top right of the page (left over from the PDF-to-text conversion). The page number is always preceded by numerous spaces on the same line. It is too cumbersome to do a traditional search-and-replace for every number (believe me, I know; I have done it). But it looks as if using the Regex function will let me automate this kind of thing.
Screenplay text
Robert,
Here is what typically happens. I will explain concisely but completely.
The standard format for a screenplay is to have the page number on a line by itself in the upper-right corner of the page. This will be in a header. The usual problem is that someone sends a PDF, which has to be converted to text and then imported into a screenwriting program or a word processor.
I use a utility that will convert PDF to formatted text. The page number ends up in the upper-right corner. For example, page 5 would appear as a 5 with a period after it, followed by a newline/hard return:
<space, space, space across an entire line at top>5.
The numbers may go up as high as '120.' or greater.
Screenwriting programs are pretty good at stripping out the page numbers from a text file when you import one. But sometimes I want to strip out the page numbers and import the file into a text editor, or import directly into Atlantis to make an ebook without page numbers.
I have not examined the regex examples yet, but I suspect that stripping out a long string of blank spaces followed by a number and a period ought to be the kind of thing that I could do with regex.
Thanks.
Roland
Here is what typically happens. I will explain concisely but completely.
The standard format for a screenplay is to have the page number on a line by itself in the upper-right corner of the page. This will be in a header. The usual problem is that someone sends a PDF, which has to be converted to text and then imported into a screenwriting program or a word processor.
I use a utility that will convert PDF to formatted text. The page number ends up in the upper-right corner. For example, page 5 would appear as a 5 with a period after it, followed by a newline/hard return:
<space, space, space across an entire line at top>5.
The numbers may go up as high as '120.' or greater.
Screenwriting programs are pretty good at stripping out the page numbers from a text file when you import one. But sometimes I want to strip out the page numbers and import the file into a text editor, or import directly into Atlantis to make an ebook without page numbers.
I have not examined the regex examples yet, but I suspect that stripping out a long string of blank spaces followed by a number and a period ought to be the kind of thing that I could do with regex.
Thanks.
Roland
Roland,
I assume that your pages are laid out in this way:

Please see attached “Page with numbers.rtf”.
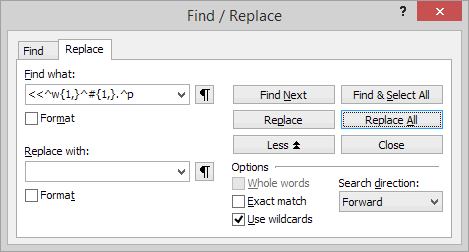
The following Find/Replace regex pattern should remove all paragraphs built as “a series of blanks + any number + a full stop + maybe a few more blanks”.
Find What pattern:
Walk-through:
<< will match the start of any paragraph.
^w{1,} will match one or more occurrences of any typographic blank (space or tab character).
^#{1,} will match one or more occurrences of any digit.
. will match itself, i.e. a full stop (period).
^w{0,} will match zero or more occurrences of any typographic blank (space or tab character). This is in case a few extra blanks might have been added after the full stop, as often happens.
^p will match the paragraph end mark.
Replace With pattern:
(empty “Replace With” box)
Walk-through:
When Atlantis replaces the text matched by the Find What pattern with nothing, this is the same as deleting it. In this case, any found sequence of “blank character(s) + digit(s) + full stop + paragraph end mark” will be removed.
When you are sure that this pattern works in the desired way, you can press the “Replace All” button in the “Ctrl+H” dialog. Also don’t forget to check the “Use wildcards” option:
HTH.
Cheers,
Robert
I assume that your pages are laid out in this way:
Please see attached “Page with numbers.rtf”.
The following Find/Replace regex pattern should remove all paragraphs built as “a series of blanks + any number + a full stop + maybe a few more blanks”.
Find What pattern:
Code: Select all
<<^w{1,}^#{1,}.^w{0,}^p<< will match the start of any paragraph.
^w{1,} will match one or more occurrences of any typographic blank (space or tab character).
^#{1,} will match one or more occurrences of any digit.
. will match itself, i.e. a full stop (period).
^w{0,} will match zero or more occurrences of any typographic blank (space or tab character). This is in case a few extra blanks might have been added after the full stop, as often happens.
^p will match the paragraph end mark.
Replace With pattern:
(empty “Replace With” box)
Walk-through:
When Atlantis replaces the text matched by the Find What pattern with nothing, this is the same as deleting it. In this case, any found sequence of “blank character(s) + digit(s) + full stop + paragraph end mark” will be removed.
When you are sure that this pattern works in the desired way, you can press the “Replace All” button in the “Ctrl+H” dialog. Also don’t forget to check the “Use wildcards” option:
HTH.
Cheers,
Robert
- Attachments
-
- Page with numbers.rtf
- (2.33 KiB) Downloaded 585 times
regex and page numbers
Thanks, Robert ...
I will check it out and let you know how it works!
Roland
I will check it out and let you know how it works!
Roland